네이버 금융: 기업의 분기별 실적 데이타 추출
분기실적을 찾아서: 키움 OPENAPI, 기업 공시 시스템 DART API, 네이버금융
기업별 분기실적 데이타를 추출하여 데이타베이스에 구축할 필요가 있어 분기실적 데이타를 추출하는 방법에 대해서 고민해 보았다.
1. 키움 OPENAPI
키움에서 제공하는 기업정보에 회사의 매출액, 영업이익, 당기순이익과 같은 지표들이 제공된다. 하지만 확인해 보니 이 데이타들은 모두 당해 년도가 아닌 직전 년도의 연간실적 데이타들이다. 즉, 분기실적 같은 정보는 없다는 뜻.
OPENAPI를 처음 사용시작 할 때만 하더라도 이러한 정보들이 키움 데이타베이스에 다 있을 거라고 생각했었다. 생각해보면 이 정도 정보가 그다지 구하기 힘든 기업비밀정보도 아니니 그렇게 생각한게 당연했다. 하지만, 키움증권의 API액세스로 당연히 분기 실적 정도는 가져올 수 있을 줄 알았는데 없어 실망했다. 그래서 다른 방법을 찾아보기로 한다. 한국의 기업 전자 공시 시스템이 있고 이 데이타에 접근가능하도록 API를 제공해준다는 것을 검색으로 알았다. 당연히 가장 최신의 정보를 실적 발표 당일에도 바로 액세스 가능하므로 모든 문제는 해결될 것으로 기대했다.
2. 기업 전자 공시 시스템 Dart API
기업들은 3월 9월 분기 실적 보고서를 6월에 반기실적 보고서 그리고 12월 연간실적 보고서를 내는데 이 보고서들을 전자공시시스템을 이용하여 조회가 가능하다. 프로그래밍도 가능하게끔 Dart API를 제공한다.
전자공시시스템 - 대한민국 기업정보의 창, DART
dart.fss.or.kr
이 시스템을 사용하는데 몇가지 문제점이 있는데
첫째, 너무 느리다. 보고서가 파싱되어 데이타베이스화 되어 있지 않다. 그러므로, 내가 원하는 부분만 API를 사용하여 받는 것이 불가능하고 전체 보고서를 받아서 내 컴퓨터에서 파싱을 해야 한다. 코스닥, 코스피 3천개 기업의 최근 연간 보고서를 다 받아서 파싱해내는 대공사를 한다는 것이 쉬운일은 아니다. 여튼 하나의 보고서를 시험삼아 다운받아 봤는데 짜증날 정도로 느리다.
둘째, 많은 데이타의 가공을 필요로 한다. 앞서 말했듯이 보고서를 받아서 파싱을 하는 것이 또 만만하지가 않은데, 원인은 회사마다 약간씩 보고서 형태가 달라 예외처리를 많이 해주어야 한다. 예를 들어 "매출액"을 알고싶어 문자열 파싱을 하더라도 "매출액"이나 "매 출 액"처럼 빈 공백이 들어간다든지 해서 노력과 시간이 더 든다.
셋째, 내가 원하는 건 3월 6월 9월 12월 분기별 실적인데, 보고서는 분기, 반기, 연간 보고서 형태여서 6월 분기실적 값을 알려면 6월 반기실적에서 3월 분기실적을 빼는 식으로 데이타의 재가공 노력이 들어가야 한다.
이 시스템을 사용하는데 좋은 점은 딱 한가지다. 기업이 실적공시를 하자마자 가장 최근의 데이타를 받을 수 있다는 점.
결국 이 시스템을 사용하는 것이 노력 또는 들여야 하는 공력 대비 그리 가성비가 좋지 않음을 느꼈다. 소프트웨어 엔지니어로서 생각하기에 어떤 데이타베이스의 API를 제공한다면 이런 데이타 추출 정도는 쉽게 되어야 하는것 아닌가? 정말 허접하기 그지없다. 그래서 투자기업에게서 또는 슈퍼개미 같은 개인에게서 비싼 돈을 받고 시스템을 만들어 주는 것인지도 모르겠다. 아니면 내가 좋은 API를 제공하는 시스템을 제대로 된 검색으로 못찾아서 그럴 수도 있다.
3. 네이버 금융
https://finance.naver.com/item/main.nhn?code=종목코드
위 URL에 종목코드를 붙이는 형태로 기업의 분기별 실적표를 html 포맷으로 받을 수 있다. 정말 행복하게도 위 Dart API의 문제점을 모두 해결해서 분기별 정제된 데이타를 html로부터 파싱하여 내 데이타베이스에 넣으면 된다.
하지만, 전자공시시스템의 장점은 잃는다. 즉, 기업공시가 최근에 이루어지더라도 바로 반영되지 않고 적어도 한달 이상 있어야 업데이트가 되는 것으로 보인다.
네이버 금융 사이트는 네이버가 제공하는 API의 목록에 아직 포함되지는 않는다. 그러므로, 웹페이지를 크롤링해와서 파싱하는 방식으로 데이타를 추출이 가능하다. 내가 원하는 분기실적 데이타를 비교적 쉽게 파싱해 받아 올 수 있다는 점은 좋다. 그러나 이런 웹페이지 파싱의 문제점은 웹페이지 레이아웃이 바뀌면 크롤링 & 파싱 스크립트가 무용지물이 되고 다시 만들어줘야 한다는 것이다. 그리고, 또 한가지 단점은 최신 실적 업데이트가 느리다는 것이다.

데이타베이스 구축 전략
여기까지 정보들이 모여서 내가 생각한 방법은 다음과 같다. 어찌 되었건 느린 속도를 극복하려면 로컬 데이타베이스가 필요하다. 그럼 어떻게 데이타베이스를 만들까? 간단히 테이블 구조도 같이 생각해 보았다.
1. 키움 OPENAPI를 사용하여 코스피/코스닥 기업의 종목코드와 기업명 데이타베이스를 구축한다.
| 종목코드 (Primary key) |
종목명 | ... |
| 005930 | 삼성전자 | ... |
| ... | ... | ... |
이건 이미 했다. (이전 포스팅 참고)
kospi kosdaq 두개의 테이블을 위와 같이 만들고 키움 OpenAPI로 종목 정보를 긁어와서 두 테이블에 각각 기업정보들을 담았다. 이후에 입력일자 필드를 추가해서 오늘 날짜가 아니면 업데이트가 되도록 수정도 해줬다.
2. 데이타베이스의 종목코드로 네이버금융에서 모든기업의 분기별 실적 데이타베이스를 구축한다.
| 종목코드 | 분기 | 분기매출액 | ... |
| 005930 | 2020.06 | 529661 | |
| ... | ... | ... |
이건 지금 하려는 현재 포스팅 내용이다.
하나의 테이블을 만들고 종목코드와 분기일자로 Primary Key를 만들어 놓는다.
3. 네이버금융에서 누락된 가장 최근의 분기 실적 데이타를 전자공시시스템에서 파싱하여 내 데이타베이스에 빠진 부분을 채운다.
지금은 별로 해야할지 필요성을 느끼지 못하고 있다. 최신 데이타가 필요한 상황이면 이 부분을 추가하지 싶다.
1번 과정은 한 번으로 테이블 생성이 되고 추후 지속적으로 지표가 바뀌므로 테이블 레코드의 업데이트가 필요할 것이다. 2번 과정은 단 한번이면 될 것이다. 3번은 기업공시가 이루어 질때마다 2번에서 생성한 테이블에 레코드를 추가하면 될 것이다.
이렇게 데이터가 로컬에 쌓이고 나면 정확한 분기별 데이타에 기반한 PER나 멀티플(시가총액/(분기영업이익x4))을 계산하여 저평가된 회사 리스트를 추리고 조건을 좀더 걸어서 분기별 실적이 나아지고 있는 또는 전년동기 실적보다 나아지고 있는 회사만 뽑아낼 수 있는 수준이 될 것이다. 이것이 1차 스크리닝 과정이 된다.
In Code We Trust

메인 함수부터 보겠다. 정말 간단한 세줄짜리 코드다.
248. 먼저 데이타베이스를 초기화 한다. 저장할 분기실적테이블(테이블 이름: q_perf_report)이 있는지 확인하고 없으면 생성한다. 그리고, 이전에 만들어 둔 코스피/코스닥 테이블에서 종목코드만 뽑아 온다.
249. 사용자 입력을 받기로 했다. 데이타 크롤링 스크립트인데 UI까지 만들 필요는 없다고 생각해서 터미널 커맨드라인으로 입력을 받는다. 2020년 6월 분 모든 기업의 분기실적 데이타를 긁어오려면 "2020.06" 이라고 입력하면 된다.
250. 받아온 분기일자로 모든 기업의 (코스피/코스닥 종목코드로 루프를 돌며) 실적 데이타를 긁어와서 파싱을 하고 분기실적테이블에 이미 존재하는지 확인한 다음, 존재하지 않으면 테이블에 입력한다.
이제 각 함수의 내부를 들여다보자.

111. check_n_create_QPTable()함수는 말 그대로 분기실적 테이블이 존재하는지 확인하고 없으면 생성하는 함수다.
112. get_jongmokCode함수로 코스피와 코스닥 두 테이블에서 종목코드만 긁어온다.

SQL을 안다면 딱히 볼 것도 없는 내용이다. 분기 실적 테이블이 존재하는지 확인하고 없으면 테이블을 만드는데 이때 주의해야 할 것이 프라이머리 키로 종목코드와 분기를 지정했다는 것이다. 대략적인 SQL 쿼리문은 다음과 같을 것이다.
CREATE TABLE q_perf_report (종목코드 NOT NULL, 분기 NOT NULL, 매출액, ... 생략 ... , PRIMARY KEY(종목코드, 분기));
이렇게 함으로써 동일한 종목코드-분기 조합의 레코드는 이 테이블에 유니크 하며 중복 존재할 수 없다.
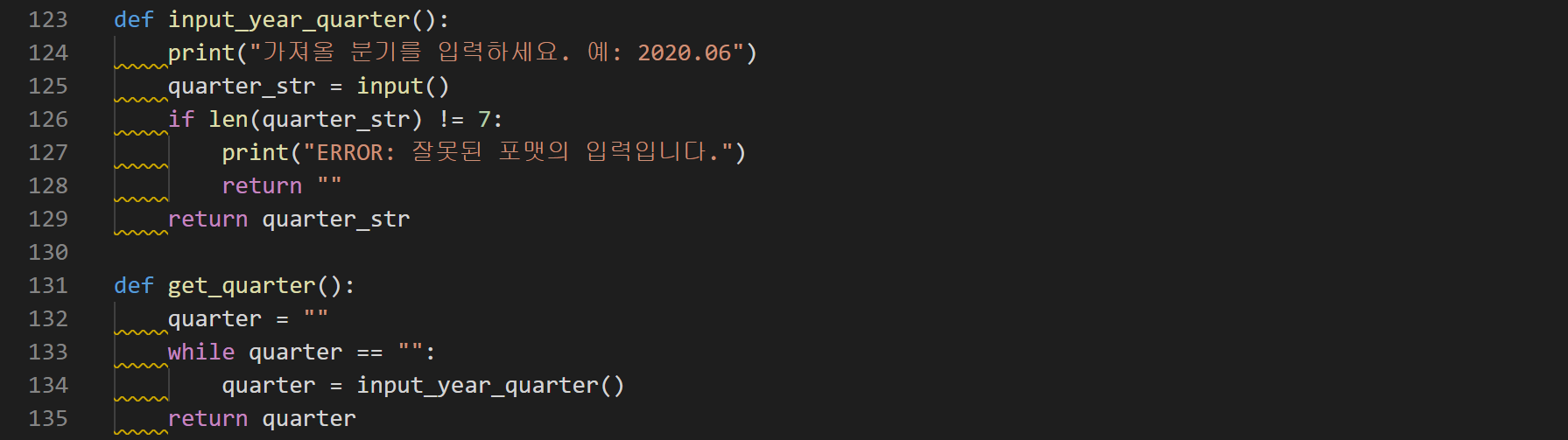
131. 메인함수에서 호출되는 get_quarter() 함수다. 터미널을 통해 사용자로부터 입력을 받는다. 입력포맷체크는 간단하게만 해두었다.

223. 메인함수에서 호출되는 함수다. 파라메터로 받은 분기값과 initDB()에서 만들어 둔 전역변수 kospi와 kosdaq의 종목코드리스트를 226. 하나로 합쳐서 전체기업 리스트 all_jongmok을 만든다.
229. for 루프를 돌면서 종목코드 하나하나 당 종목코드-분기 데이타가 이미 존재하는지 확인한다.
239. 존재하지 않으면 네이버 금융에서 종목코드에 해당하는 html을 받아와서 파싱을 한다.
244. 파싱한 데이타를 로컬 DB에 저장한다.

SELECT * FROM q_perf_report WHERE 종목코드='005930' AND 분기='2020.06';
위 예는 삼성전자의 2020년 2분기 실적이 분기실적 테이블에 존재하는지 확인하기위한 쿼리문이다.
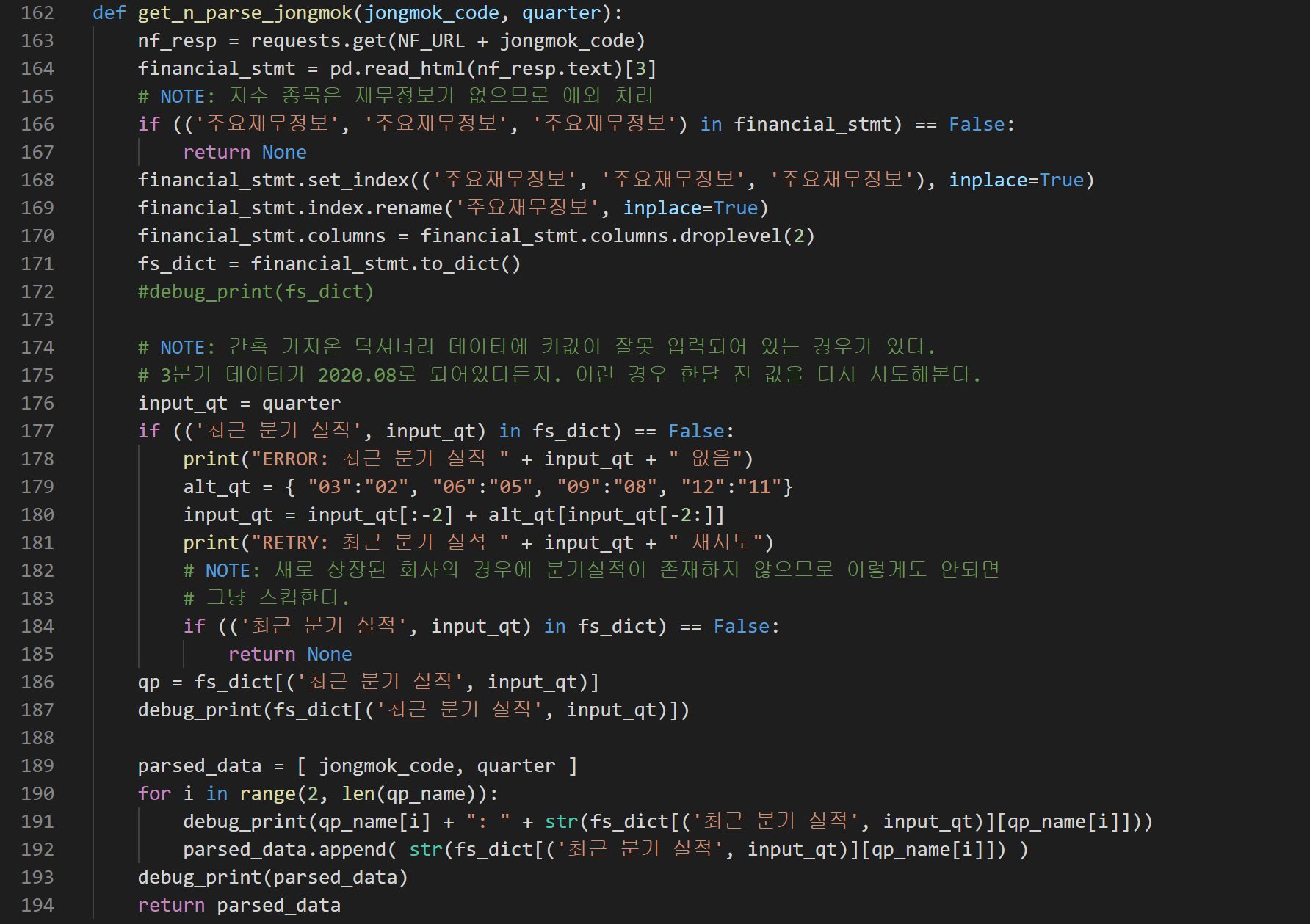
예외 처리해야 할 부분이 있어 함수가 좀 길어보이는데 사실 간단하다.
163. 네이버금융 URL https://finance.naver.com/item/main.nhn?code= 뒤에 종목코드를 붙여서 HTML 웹페이지를 긁어온다.
164. pandas의 read_html 함수로 html 문서내에서 내가 원하는 부분을 가져올 수 있다.
166. 예외 처리 부분인데, KODEX 같은 지수 종목은 당연하게도 분기실적 데이타가 없다. 이럴때 None을 리턴한다.
177~185. 또다른 예외 처리 부분이다. 간혹 실적 데이타의 분기 월이 틀리는 경우가 있다. 예를 들어 2020.06인데 2분기 실적이 2020.05로 들어가 있는 경우다. 또는 빅히트 같은 최신 상장 종목은 분기실적 데이타가 없다. 딕셔너리에서 ('최근 분기 실적', '2020.06') 을 키로 검색해서 없으면 None을 리턴한다.
189~194. 데이타를 성공적으로 뽑아내서 리스트로 만들어 리턴해준다.

뽑아낸 데이타를 insert_record()함수로 넘겨주면 insert sql문을 만들어 데이타를 DB에 입력한다.
실행하여 분기실적 테이블에 데이터 구축하기

지수 종목이나 신규 상장 회사같은 예외 상황은 잘 처리됨을 알 수 있다.

모든 종목의 2020.06 분기 데이타를 입력 완료한 모습. 전체는 3천개가 넘으나 중간에 네이버로 부터 끊겨서 다시 실행시켜야 했다. 다시 실행시키는 경우 테이블에 이미 존재하는 레코드들은 빠르게 스킵하여 다음으로 넘어가니 데이터를 안정적으로 구축할 수 있었다.
이제 로컬에 쌓인 데이터베이스로 1차 기업 스크리닝을 위한 검색 sql을 만들어 멀티플(시총/(분기영업이익x4))이 낮으면서 (PER가 낮다는 말과 유사하지만 조금 의미가 다르다.) 지속적으로 성장하는 기업을 찾아봐야 겠다.
github 소스코드
전체 소스코드는 다음 위치에서 받을 수 있다.
https://github.com/mole-cricket/kiwoom-openapi
mole-cricket/kiwoom-openapi
Contribute to mole-cricket/kiwoom-openapi development by creating an account on GitHub.
github.com